
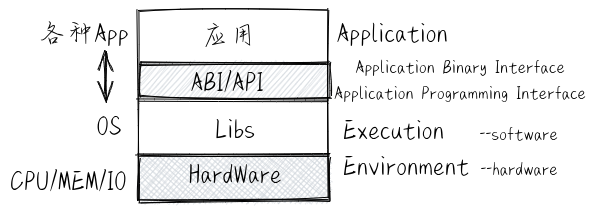
API 与 ABI 的区别
API
应用程序编程接口 API 是不同源代码片段的连接纽带。API 定义了一个源码级(如 C 语言)函数的参数,参数的类型,函数的返回值等。因此 API 是用来约束编译器 (Compiler) 的:一个 API 是给编译器的一些指令,它规定了源代码可以做以及不可以做哪些事。API 与编程语言相关,如 libc 是基于 C 语言编写的标准库,那么基于 C 的应用程序就可以通过编译器建立与 libc 的联系,并能在运行中正确访问 libc 中的函数。
ABI
应用程序二进制接口 ABI 是不同二进制代码片段的连接纽带。ABI 定义了二进制机器代码级别的规则,主要包括基本数据类型、通用寄存器的使用、参数的传递规则、以及堆栈的使用等等。ABI 与处理器和内存地址等硬件架构相关,是用来约束链接器 (Linker) 和汇编器 (Assembler) 的。在同一处理器下,基于不同高级语言编写的应用程序、库和操作系统,如果遵循同样的 ABI 定义,那么它们就能正确链接和执行。
执行环境
执行环境 (Execution Environment) 主要负责给在其上执行的软件提供相应的功能与资源,并可在计算机系统中形成多层次的执行环境。对于现在直接运行在裸机硬件 (Bare-Metal) 上的操作系统,其执行环境是 计算机的硬件 。计算机刚刚诞生时,还没有操作系统的概念,对于直接运行在裸机硬件上的应用程序而言,其执行环境也是 计算机的硬件 。 随着计算机技术的发展,应用程序下面形成了一层比较通用的函数库,这使得应用程序不需要直接访问硬件了,它所需要的功能(比如显示字符串)和资源(比如一块内存)都可以通过函数库的函数来帮助完成。在第二个阶段,应用程序的执行环境就变成了 函数库 -> 计算机硬件 ,而这时函数库的执行环境就是计算机的硬件。
再进一步,操作系统取代了函数库来访问硬件,函数库通过访问操作系统的系统调用服务来进一步给应用程序提供丰富的功能和资源。在第三个阶段,应用程序的执行环境就变成了 函数库 -> 操作系统内核 -> 计算机硬件 。在后面又出现了基于 Java 语言的应用程序,在函数库和操作系统之间,多了一层 Java 虚拟机,此时 Java 应用程序的执行环境就变成了 函数库 -> Java 虚拟机 -> 操作系统内核 -> 计算机硬件 。在云计算时代,在传统操作系统与计算机硬件之间多了一层 Hypervisor/VMM ,此时应用程序的执行环境变成了 函数库 -> Java 虚拟机 -> 操作系统内核 -> Hypervisor/VMM -> 计算机硬件 。这里可以看到,随着软件需求的多样化和复杂化, 执行环境的层次 也越来越多。
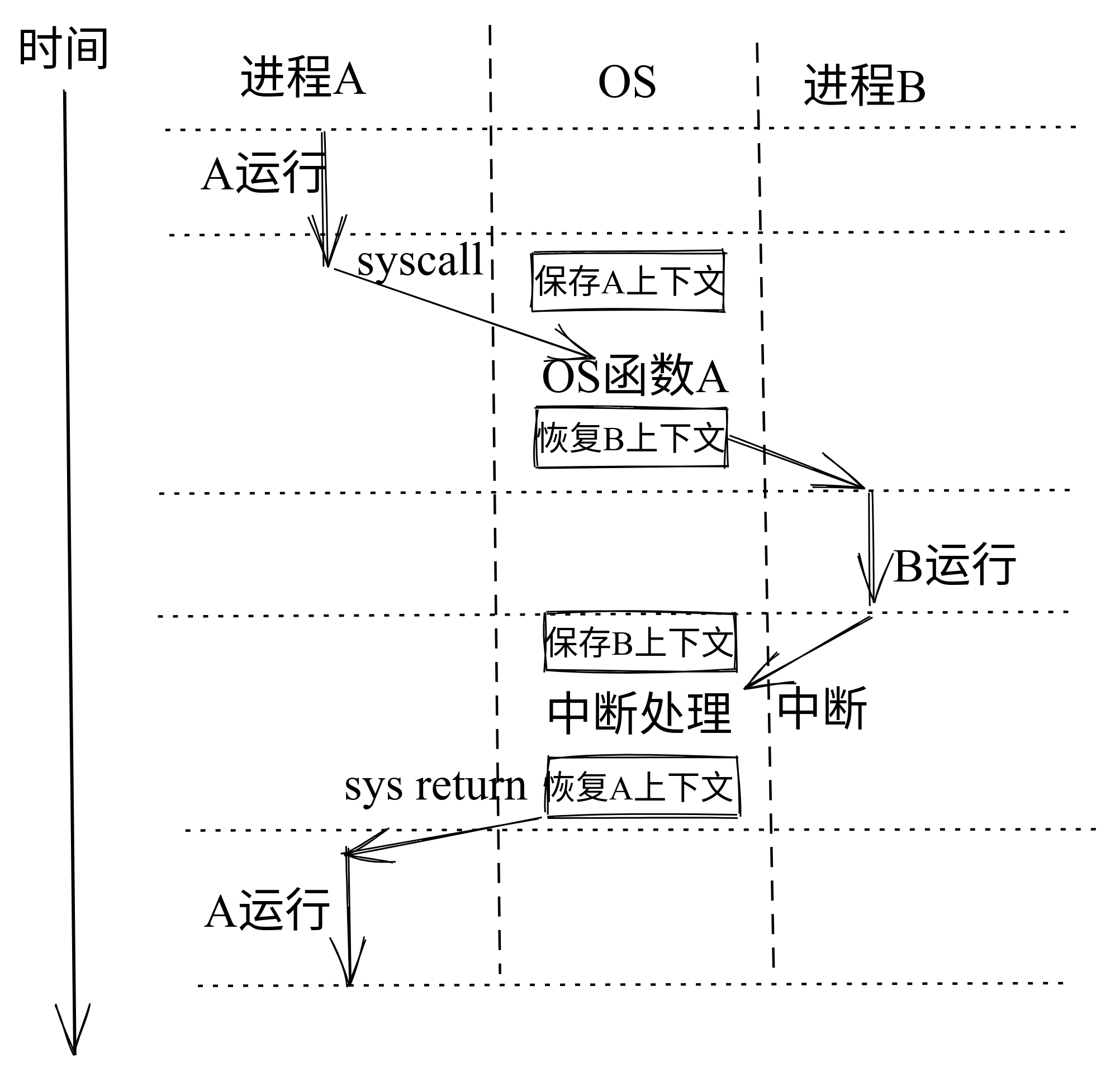
另外,CPU在执行过程中,可以在不同层次的执行环境之间切换,这称为 执行环境切换 。执行环境切换主要是通过特定的 API 或 ABI 来完成的,这样不同执行环境的软件就能实现数据交换与互操作,而且还保证了彼此之间有清晰的隔离。
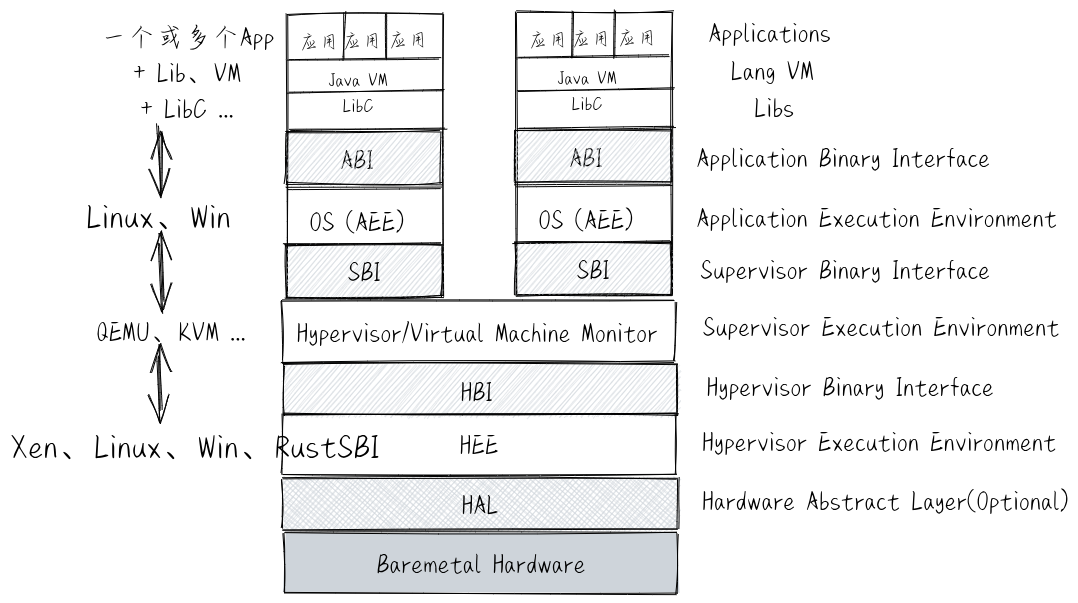
对于应用程序的执行环境而言,应用程序只能看到执行环境直接提供给它的接口(API 或 ABI),这使得应用程序所能得到的服务取决于执行环境提供给它的访问接口。
控制流
控制流上下文
(执行环境的状态)
站在硬件的角度来看普通控制流或异常控制流的具体执行过程,我们会发现从控制流起始的某条指令执行开始,指令可访问的所有物理资源的内容,包括自带的所有通用寄存器、特权级相关特殊寄存器、以及指令访问的内存等,会随着指令的执行而逐渐发生变化。
这里我们把控制流在执行完某指令时的物理资源内容,即确保下一时刻能继续 正确 执行控制流指令的物理资源内容称为控制流的 上下文 (Context) ,也可称为控制流所在执行环境的状态。
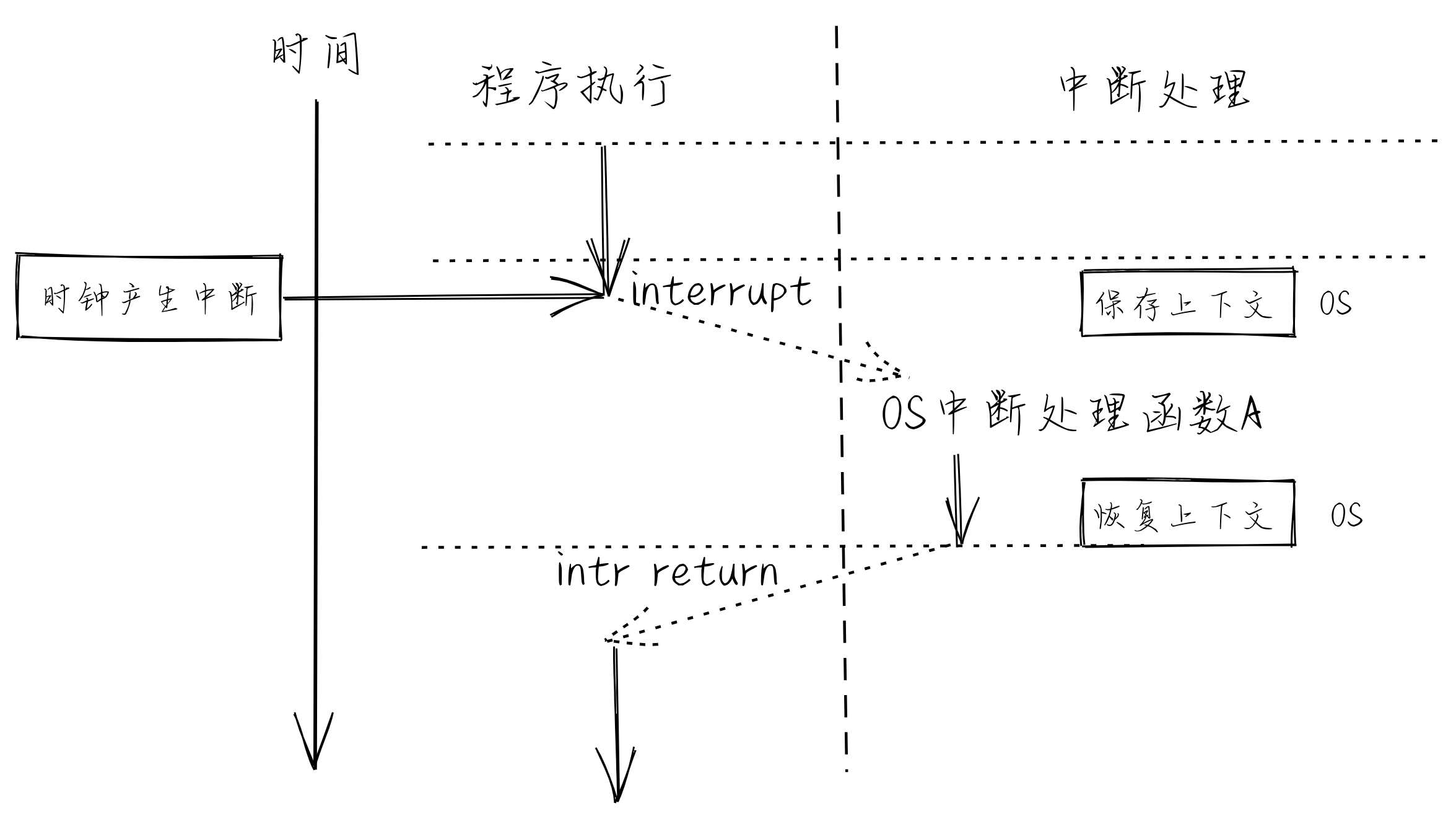
例如在中断处理前后需要保存执行程序的上下文,以便执行中断处理完毕之后恢复程序的执行
进程
定义:
站在应用程序自身的角度来看,进程 (Process) 的一个经典定义是一个正在运行的程序实例。当程序运行在操作系统中的时候,从程序的视角来看,它会产生一种“幻觉”:即该程序是整个计算机系统中当前运行的唯一的程序,能够独占使用处理器、内存和外设,而且程序中的代码和数据是系统内存中唯一的对象。
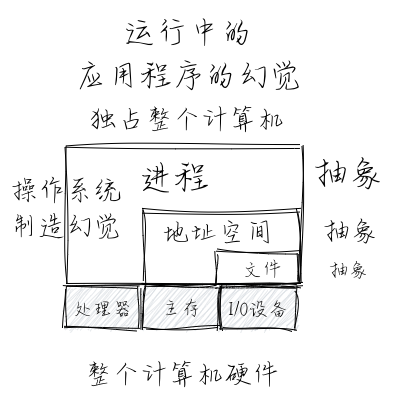
进程上下文
这里的进程上下文是指程序在运行中的各种物理/虚拟资源(寄存器、可访问的内存区域、打开的文件、信号等)的内容,特别是与程序执行相关的具体内容:内存中的代码和数据,栈、堆、当前执行的指令位置(程序计数器的内容)、当前执行时刻的各个通用寄存器中的值等。
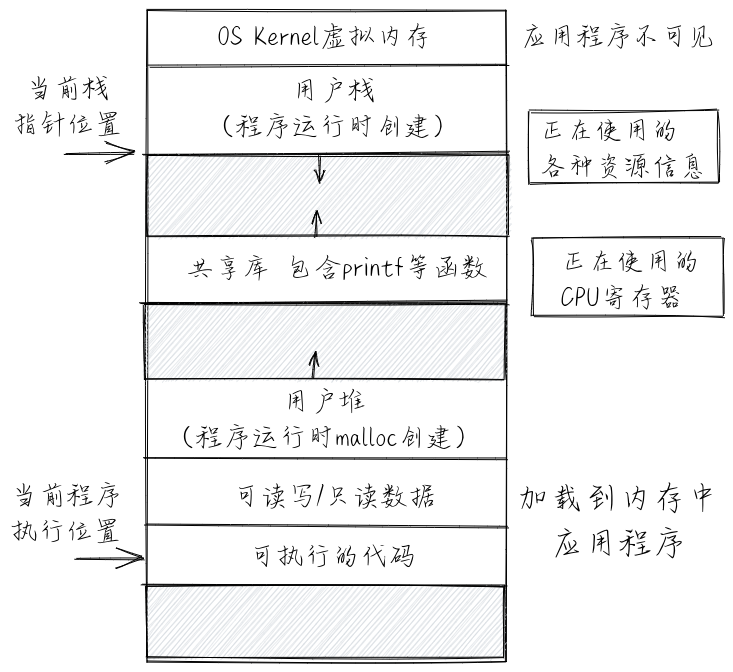
进程的切换:
文件
文件 (File) 主要用于对持久存储的抽象,并进一步扩展到为外设的抽象。具体而言,文件可理解为存放在持久存储介质(比如硬盘、光盘、U盘等)上,方便应用程序和用户读写的数据。以磁盘为代表的持久存储介质的数据访问单位是一个扇区或一个块,而在内存中的数据访问单位是一个字节或一个字。这就需要操作系统通过文件来屏蔽磁盘与内存差异,尽量以内存的读写方式来处理持久存储的数据。当处理器需要访问文件中的数据时,可通过操作系统把它们装入内存。文件管理的任务是有效地支持文件的存储、 检索和修改等操作。
下面是文件对磁盘的抽象映射图示:
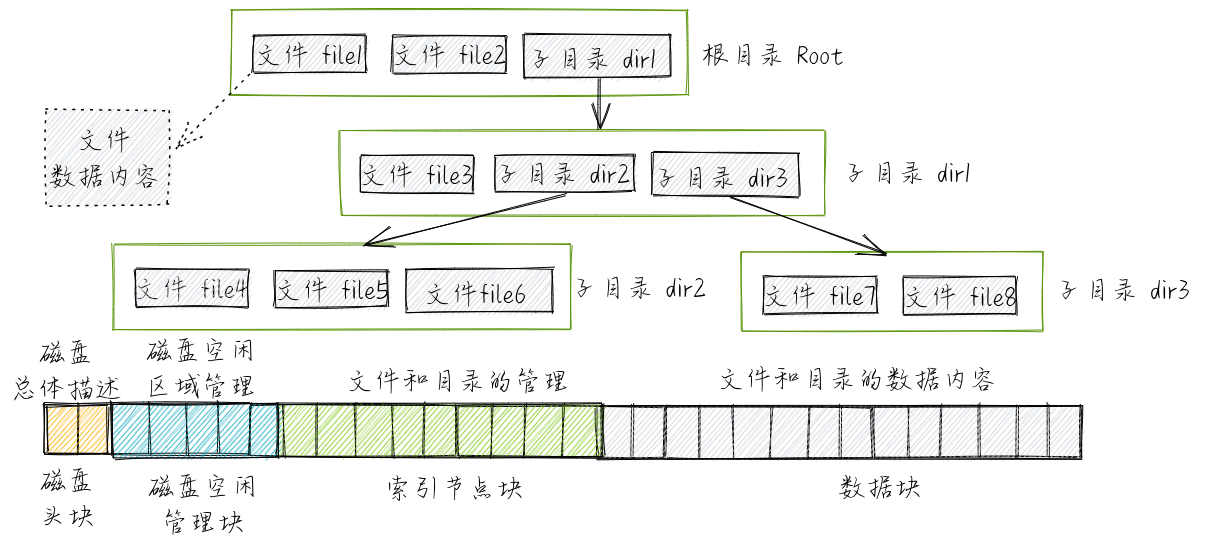
从一个更高和更广泛的层次上看,各种外设虽然差异很大,但也有基本的读写操作,可以通过文件来进行统一的抽象,并在操作系统内部实现中来隐藏对外设的具体访问过程,从而让用户可以以统一的文件操作来访问各种外设。这样就可以把文件看成是对外设的一种统一抽象,应用程序通过基本的读写操作来完成对外设的访问。
Qemu模拟器
运行内核
可以使用如下的命令来启动Qemu并运行内核
1 | qemu-system-riscv64 \ |
通过 -bios 可以设置 Qemu 模拟器开机时用来初始化的引导加载程序(bootloader),这里我们使用预编译好的 rustsbi-qemu.bin ,它需要被放在与 os 同级的 bootloader 目录下
通过虚拟设备 -device 中的 loader 属性可以在 Qemu 模拟器开机之前将一个宿主机上的文件载入到 Qemu 的物理内存的指定位置中, file 和 addr 属性分别可以设置待载入文件的路径以及将文件载入到的 Qemu 物理内存上的物理地址。这里我们载入的 os.bin 被称为 内核镜像 ,它会被载入到 Qemu 模拟器内存的 0x80200000 地址处。
启动流程
virt硬件平台上:物理内存的起始物理地址为 0x80000000 ,物理内存的默认大小为 128MiB ,它可以通过 -m 选项进行配置。如果使用默认配置的 128MiB 物理内存则对应的物理地址区间为 [0x80000000,0x88000000) 。
如果使用上面给出的命令启动 Qemu ,那么在 Qemu 开始执行任何指令之前,首先把两个文件加载到 Qemu 的物理内存中:即作把作为 bootloader 的 rustsbi-qemu.bin 加载到物理内存以物理地址 0x80000000 开头的区域上,同时把内核镜像 os.bin 加载到以物理地址 0x80200000 开头的区域上。
三个阶段
第一阶段:
将必要的文件载入到 Qemu 物理内存之后,Qemu CPU 的程序计数器(PC, Program Counter)会被初始化为 0x1000 ,因此 Qemu 实际执行的第一条指令位于物理地址 0x1000 ,接下来它将执行寥寥数条指令并跳转到物理地址 0x80000000 对应的指令处并进入第二阶段。
第二阶段:
由于 Qemu 的第一阶段固定跳转到 0x80000000 ,我们需要将负责第二阶段的 bootloader rustsbi-qemu.bin 放在以物理地址 0x80000000 开头的物理内存中,这样就能保证 0x80000000 处正好保存 bootloader 的第一条指令。
第三阶段:
为了正确地和上一阶段的 RustSBI 对接,我们需要保证内核的第一条指令位于物理地址 0x80200000 处。为此,我们需要将内核镜像预先加载到 Qemu 物理内存以地址 0x80200000 开头的区域上。一旦 CPU 开始执行内核的第一条指令,证明计算机的控制权已经被移交给我们的内核
程序内部布局
源代码编译为可执行文件之后,它就会变成一个看似充满了杂乱无章的字节的一个文件。但我们知道这些字节至少可以分成代码和数据两部分
还可以根据其功能进一步把两个部分划分为更小的单位: 段 (Section) 。不同的段会被编译器放置在内存不同的位置上,这构成了程序的 内存布局,如下所示:
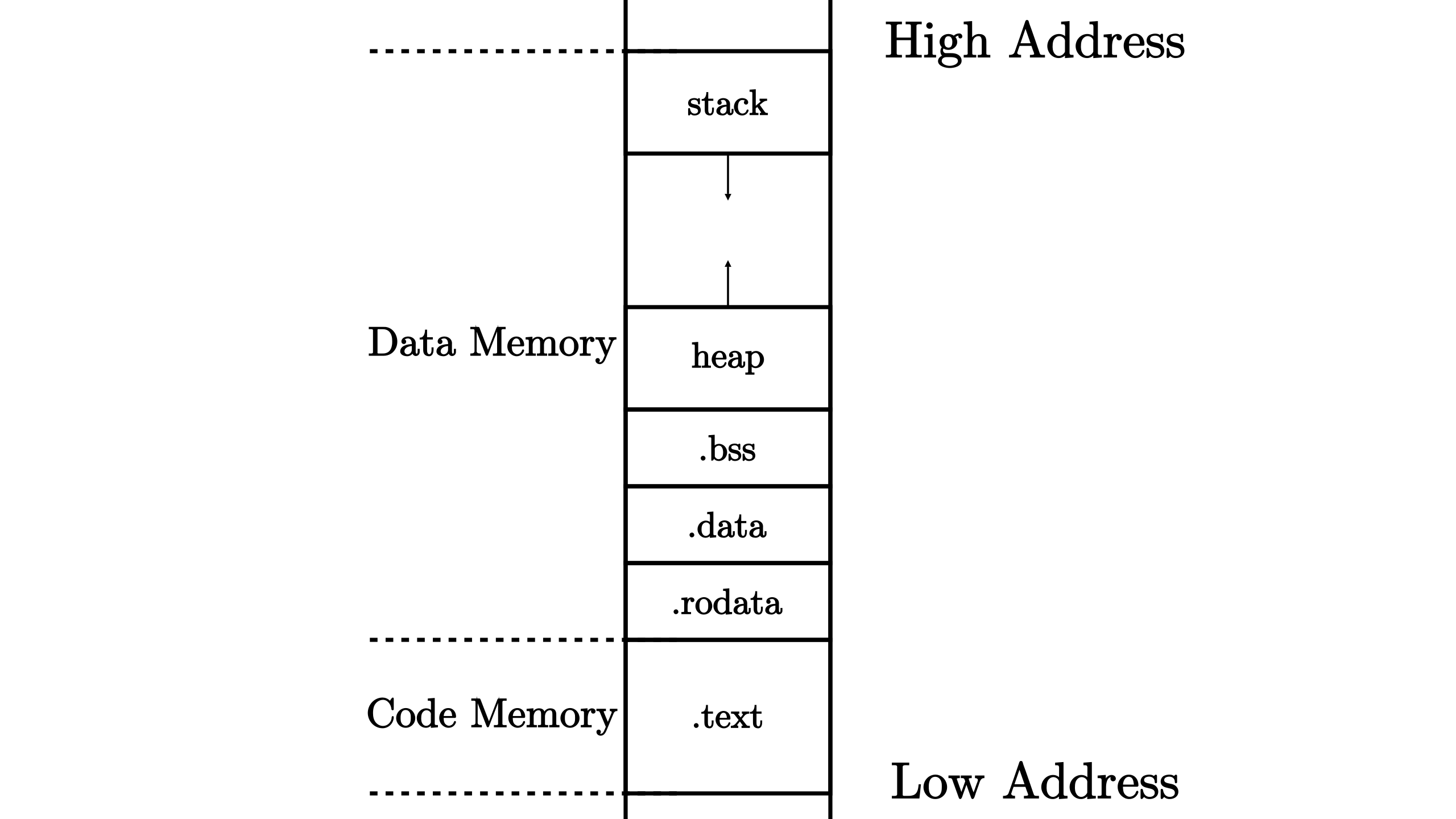
在上图中可以看到,代码部分只有代码段 .text 一个段,存放程序的所有汇编代码。而数据部分则还可以继续细化:
- 已初始化数据段保存程序中那些已初始化的全局数据,分为
.rodata和.data两部分。前者存放只读的全局数据,通常是一些常数或者是 常量字符串等;而后者存放可修改的全局数据。 - 未初始化数据段
.bss保存程序中那些未初始化的全局数据,通常由程序的加载者代为进行零初始化,即将这块区域逐字节清零; - 堆 (heap)区域用来存放程序运行时动态分配的数据,如 C/C++ 中的 malloc/new 分配到的数据本体就放在堆区域,它向高地址增长;
- 栈 (stack)区域不仅用作函数调用上下文的保存与恢复,每个函数作用域内的局部变量也被编译器放在它的栈帧内,它向低地址增长。
编译流程
前置知识
- 编译器 (Compiler) 将每个源文件从某门高级编程语言转化为汇编语言,注意此时源文件仍然是一个 ASCII 或其他编码的文本文件;
- 汇编器 (Assembler) 将上一步的每个源文件中的文本格式的指令转化为机器码,得到一个二进制的 目标文件 (Object File);
- 链接器 (Linker) 将上一步得到的所有目标文件以及一些可能的外部目标文件链接在一起形成一个完整的可执行文件。
汇编器输出的每个目标文件都有一个独立的程序内存布局,它描述了目标文件内各段所在的位置。而链接器所做的事情是将所有输入的目标文件整合成一个整体的内存布局。
编译链接过程
第一件事情
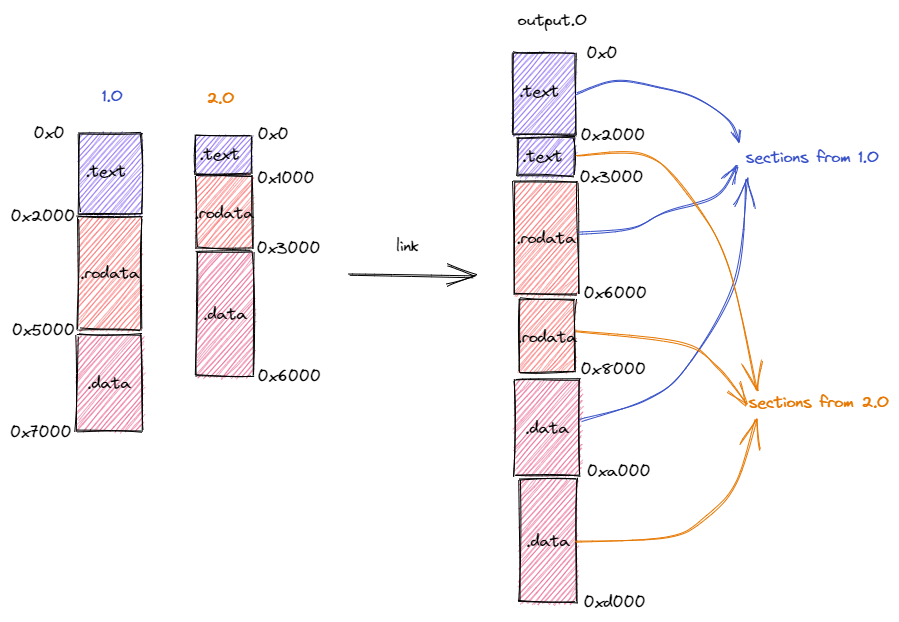
将来自不同目标文件的段在目标内存布局中重新排布。如下图所示,在链接过程中,分别来自于目标文件 1.o 和 2.o 段被按照段的功能进行分类,相同功能的段被排在一起放在拼装后的目标文件 output.o 中
第二件事情
将符号替换为具体地址。这里的符号指什么呢?我们知道,在我们进行模块化编程的时候,每个模块都会提供一些向其他模块公开的全局变量、函数等供其他模块访问,也会访问其他模块向它公开的内容。要访问一个变量或者调用一个函数,在源代码级别我们只需知道它们的名字即可,这些名字被我们称为符号。
当一个模块被转化为目标文件之后,它的内部符号就已经在目标文件中被转化为具体的地址了,因为目标文件给出了模块的内存布局,也就意味着模块内的各个段的位置已经被确定了。然而,此时模块所用到的外部符号的地址无法确定。我们需要将这些外部符号记录下来,放在目标文件一个名为符号表(Symbol table)的区域内。由于后续可能还需要重定位,内部符号也同样需要被记录在符号表中,外部符号需要等到链接的时候才能被转化为具体地址。
注意:两个模块的段在合并后的内存布局中被重新排布,其最终的位置有可能和它们在模块自身的局部内存布局中的位置相比已经发生了变化。因此,每个模块的内部符号的地址也有可能会发生变化,我们也需要进行修正。上面的过程被称为重定位(Relocation),这个过程形象一些来说很像拼图:由于模块 1 用到了模块 2 的内容,因此二者分别相当于一块凹进和凸出一部分的拼图,正因如此我们可以将它们无缝地拼接到一起。